Como Utilizar Machine Learning com Python no PowerBI: Um Guia Básico
Você já se perguntou como levar sua análise de dados no PowerBI para o próximo patamar? Já imaginou integrar machine learning na equação? Se sim, você está no lugar certo. Este artigo serve como um ponto de partida para quem quer descobrir o poder de combinar machine learning com Python no PowerBI. Simples e direto ao ponto, vamos desmistificar como essa integração é não só possível, mas também acessível, mesmo para quem está começando.
Como o Machine Learning Funciona: Um Guia Simples

Se você já ouviu falar de ‘machine learning’ ou aprendizado de máquina, mas não tem certeza do que realmente significa, você não está sozinho. Machine learning é um subcampo da inteligência artificial (IA) que permite que computadores aprendam diretamente de exemplos e experiência, sem serem programados de forma explícita. Pense nele como um método que treina computadores para aprender com dados, da mesma forma que um ser humano aprenderia com a experiência.
Mas como exatamente funciona esse aprendizado de máquina? Em termos simples, o machine learning utiliza algoritmos e modelos estatísticos para analisar padrões em dados. Assim como você aprenderia a diferenciar uma maçã de uma banana observando suas características, um computador pode ser ‘treinado’ para fazer o mesmo analisando grandes volumes de dados.
Então, por que isso é importante para quem usa PowerBI? A resposta é simples: integrar machine learning com PowerBI abre portas para análises de dados mais inteligentes e automatizadas. Você pode, por exemplo, utilizar essa tecnologia para prever tendências de vendas ou para identificar oportunidades de otimização nos processos da empresa.
Utilizando Python para Machine Learning no PowerBI
Bom, vamos ao que realmente importa: a integração do PowerBI com machine learning através da linguagem de programação Python. Para demonstrar isso, utilizaremos um conjunto de dados focado na previsão de diabetes, disponibilizado pela plataforma Kaggle.
Devido ao fato de que o arquivo está no formato americano — onde o separador decimal é um ponto — realizamos um pequeno tratamento nos dados para alterar o separador para vírgula. Se você deseja baixar este arquivo tratado, ele está disponível aqui.
Com o PowerBI já aberto, o próximo passo é conectar a base de dados que será utilizada para nossa análise. Fazer isso é simples:
- Clique na opção ‘Obter Dados’.
- Em seguida, escolha a opção ‘Texto/CSV’.
Essas ações irão permitir que você importe o conjunto de dados necessário diretamente para o PowerBI.
Após selecionar o arquivo ‘diabetes.csv’, você será redirecionado para a tela de carga de dados. Neste estágio, é crucial clicar em ‘Transformar Dados’. Isso nos permitirá iniciar o processo de escrita do código em Python responsável pela classificação que determinará se a pessoa tem ou não diabetes.
Após clicar em ‘Transformar Dados’, você será direcionado para a área de tratamento de dados dentro do ‘Editor do Power Query’.
Neste ponto, você tem a liberdade de fazer quaisquer alterações que considere necessárias na base de dados. Mas, para os propósitos deste tutorial, não serão necessárias mudanças adicionais, pois o conjunto de dados já atende aos requisitos necessários.
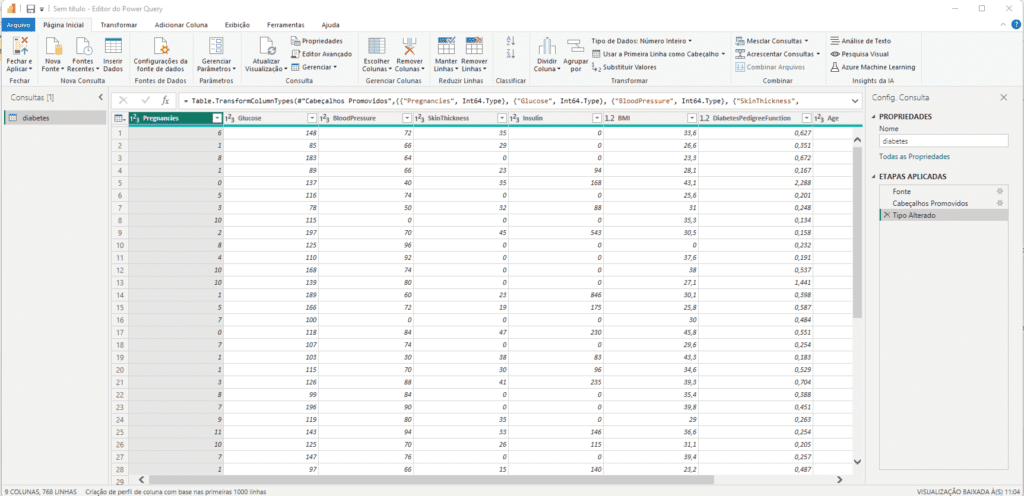
Agora, você deve acessar o menu ‘Transformar’ e, logo em seguida, selecionar ‘Executar Script Python’. Nesta opção, um campo será disponibilizado para que você insira o código Python responsável pela classificação que determinará se a pessoa tem ou não diabetes.
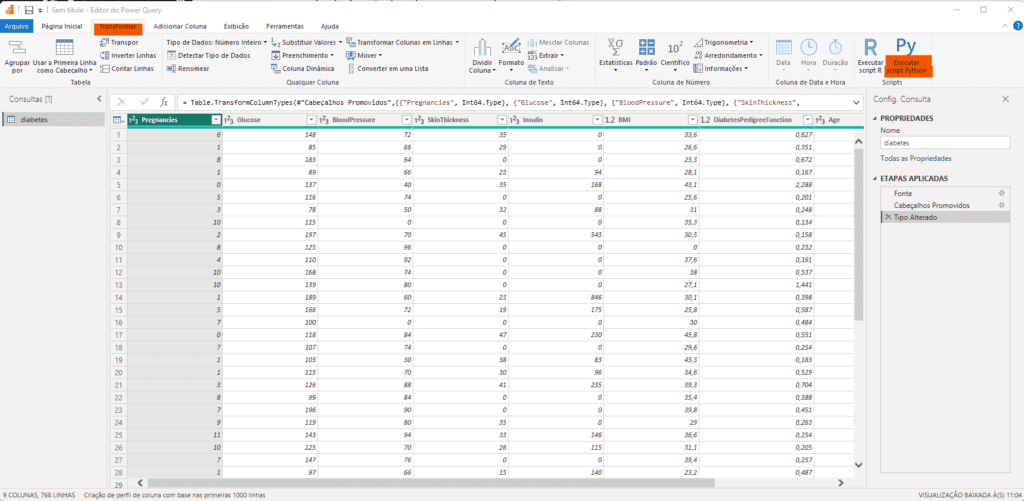
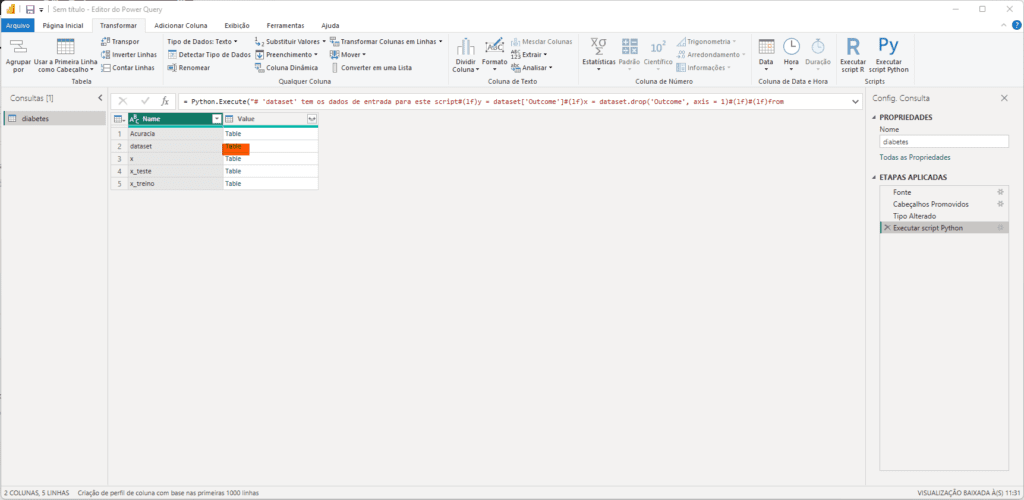
Ao selecionar ‘Executar Script Python’, será apresentada a tela onde você deverá inserir o código-fonte que fará a classificação dos registros. A seguir, apresentamos o script Python utilizado neste tutorial para realizar a classificação:
# ‘dataset’ contém os dados de entrada para este script
y = dataset[‘Outcome’]
x = dataset.drop(‘Outcome’, axis = 1)
# Dividindo o conjunto de dados para treinamento e teste
from sklearn.model_selection import train_test_split
x_treino, x_teste, y_treino, y_teste = train_test_split(x, y, test_size = 0.30)
# Utilizando o algoritmo ExtraTreesClassifier para o modelo de classificação
from sklearn.ensemble import ExtraTreesClassifier
modelo = ExtraTreesClassifier()
modelo.fit(x_treino, y_treino)
# Calculando a acurácia do modelo
Acuracia = pandas.DataFrame([modelo.score(x_treino, y_treino)])
dataset[‘Previsao’] = modelo.predict(x)
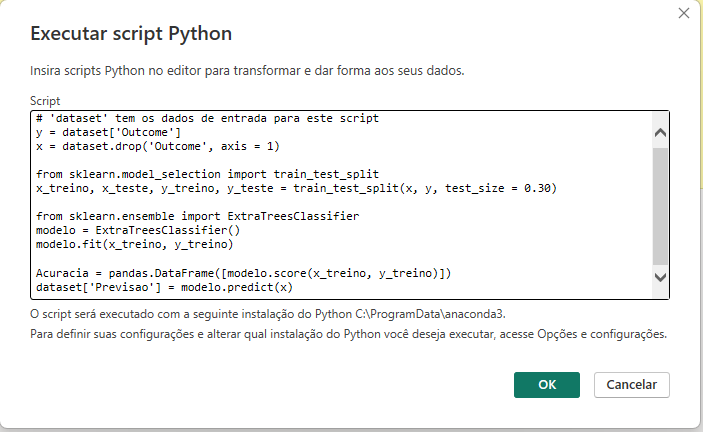
Após concluir a digitação do código-fonte e executá-lo pela primeira vez, o Power BI exibirá uma tela relacionada à privacidade dos dados. Nesta tela, você tem a opção de marcar ‘Ignorar verificações de Níveis de Privacidade para esse arquivo.’ e, em seguida, clicar em ‘Salvar’. Esta etapa é necessária para permitir que o código seja executado sem interrupções relacionadas à privacidade dos dados.
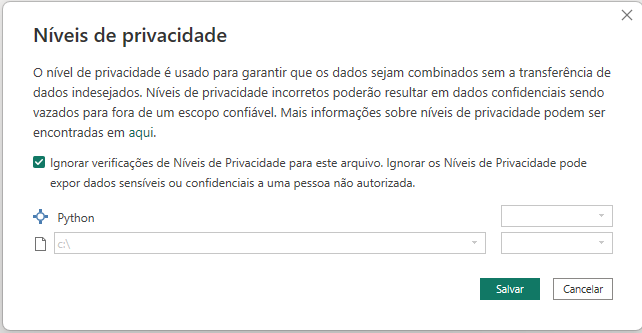
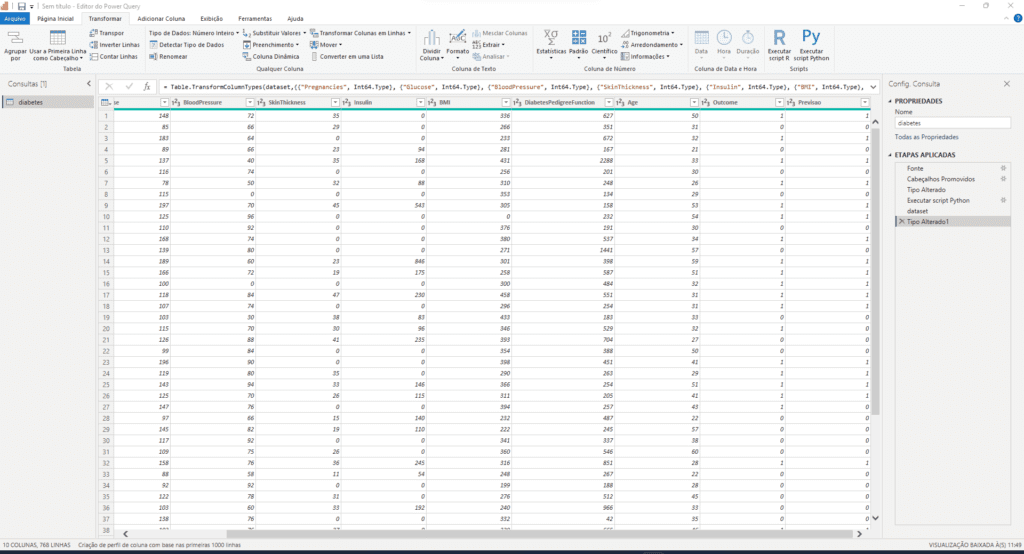
Pronto, agora você possui uma base de dados que irá classificar se a pessoa tem diabetes ou não.
Para visualizar esses dados, clique em ‘Table’, que fica ao lado da palavra ‘Dataset’. Você notará que uma nova coluna chamada ‘Previsão’ foi adicionada aos dados. Este campo contém as previsões geradas pelo código-fonte que implementamos.
Concluindo, vimos neste tutorial o potencial incrível de combinar Machine Learning com Power BI para classificar se uma pessoa tem ou não diabetes. A integração dessas duas tecnologias oferece um mundo de possibilidades para análise de dados e tomada de decisões baseadas em insights concretos.
Se você está interessado em alavancar o poder da análise de dados em seu próprio negócio ou projeto, espero que este guia tenha servido como um excelente ponto de partida. Lembre-se, o que mostramos aqui é apenas a ponta do iceberg; há muitas outras maneiras de aplicar machine learning em conjunto com Power BI para resolver problemas complexos e gerar valor.
Ficou com alguma dúvida ou tem experiências próprias para compartilhar? Deixe seu comentário abaixo ou entre em contato conosco. Estamos sempre em busca de novas maneiras de inovar e adoraríamos ouvir suas ideias!
Explorando Horizontes: Descubra Mais Inovações
- Impacto da Transformação Digital nas Profissões até 2027
- Software Legado: Redesenhar o Passado para um Futuro mais Eficiente
- Navegando pela Transformação: Um Guia de Gestão de Mudanças para Empresas Inovadoras
- Desvendando o Universo dos Softwares: Uma Jornada de Inovação e Facilidade
- Jornada de Transformação Digital: O Caminho para um Futuro Inovador
- Rumo à Excelência: Descobrindo os Níveis de Maturidade de Processos Administrativos
- Como Implementar a Otimização e Automatização de Processos para Alavancar seu Negócio
- Como uma consultoria de TI pode alavancar o seu pequeno negócio
- Por que Contratar uma Consultoria de TI? Descubra os Benefícios e Impactos Positivos
- A Eficiência de um Processo: 5 Dicas para Aumentar sua Produtividade
- Mapeamento de Processos: O Primeiro Passo para a Eficiência Operacional
- Por que a colaboração é fundamental no processo de desenvolvimento de software
- Otimizando Eficiência e Custos: O Guia do Smart Process
- 10 Termos/Palavras Relacionados ao Mundo da Tecnologia
- Como a Inteligência Artificial Está Redefinindo o Jogo dos Negócios
- O Que é TIC? Entenda Sua Importância e Impacto
- Transformando o Cenário Empresarial com BPM: O Que Você Precisa Saber
- Como a Transformação Digital Pode Resolver Problemas Comuns em PMEs
- Transformação Digital em PMEs: Mitos e Verdades
- A Importância do Ciclo PDCA na Melhoria Contínua de Processos
- Desmistificando Scrum: Como ele Se Encaixa na Cultura de Inovação
- Kanban: Como Otimizar a Gestão de Demandas em Sua Empresa
- Instalando Python no Windows
- Software Feito Sob Medida: Elevando Negócios e Encarando Desafios com a GKFTech.
Segunda à Sexta-Feira
contato@gkftech.com.br
das 08:00 às 18:00
© 2023 GKFTech Sistemas. Todos os direitos reservados